

Digital gebrandmarkt
Wie Konsumentendaten gesammelt, gehandelt und genutzt werden
Algorithmen werten in großem Stil hinterrücks gesammelte Daten aus und prognostizieren Kreditwürdigkeit, Verhalten oder Gesundheit von Bürgern. Wo die eigenen Daten nicht reichen, kaufen Unternehmen fremde zu. Die Gefahr wächst, dass wir uns durch Big Data und Mathematik steuern und diskriminieren lassen.
Menschen sind dort besonders gut auszuspähen, wo sie sich sicher und unbeobachtet fühlen. Angenommen, Sie haben Probleme in der Beziehung und wollen einen Paartherapeuten konsultieren. Davon erzählen Sie nicht einmal den engsten Freunden. Aber würden Sie bei der Wahl und der Bezahlung dieses Therapeuten darüber nachdenken, ob damit Ihre Kreditwürdigkeit auf dem Spiel stehen könnte? Sicher nicht.
Ein US-amerikanisches Kreditkarten-Unternehmen dachte da einige Schritte weiter. Es war auf eine Korrelation zwischen Beziehungsproblemen und potenziellen finanziellen Belastungen in der Zukunft gestoßen: Wer sich scheiden lässt, gerät eher in finanzielle Schieflage. Das Unternehmen kürzte daraufhin Ehepartnern, die über ihre Kreditkarte eine Paartherapie buchten, die Kreditlinie, wie der Harvard-Juraprofessor Frank Pasquale nachwies [1].
Das Vorgehen wäre in Deutschland sicher nicht rechtmäßig (siehe Artikel auf S. 76). Dennoch zeigt das Beispiel, wie Datenanalysten aus einfachen Korrelationen Modelle, Vorhersagen und Anweisungen bauen. Meist geschieht das hinter dem Rücken der Betroffenen.
Unternehmen aus aller Welt sammeln und bewerten pausenlos persönliche Daten und verwenden sie dazu, zu analysieren, zu durchleuchten und digitale Stempel aufzudrücken. Jeder Zahlvorgang, jede Suchanfrage, jedes Posting in sozialen Netzen wird registriert; Smartphone und Fitnessarmband pumpen Standort und Vitalwerte in die Hersteller-Cloud und auch an vielen völlig unerwarteten Stellen hinterlässt jeder von uns auswertbare Datenspuren.
Wer meint, doch „nichts zu verbergen“ zu haben, verkennt die Tragweite der Informationen, die sich aus Daten destillieren lassen: Unternehmen nutzen sie in großem Maßstab dazu, um auf Charaktereigenschaften, Leistungsfähigkeit, Intelligenz, Gemütsverfassung, Bildungsniveau, Krankheitswahrscheinlichkeiten, psychopathische Veranlagung, Kreditwürdigkeit und viele andere Eigenschaften von Menschen zu schließen – und dies oft ohne deren Wissen. Sind Sie ein wertvoller Kunde, ein loyaler Arbeitnehmer, ein vorbildliches Krankenversicherungsmitglied – oder eben nicht?
Anreicherung
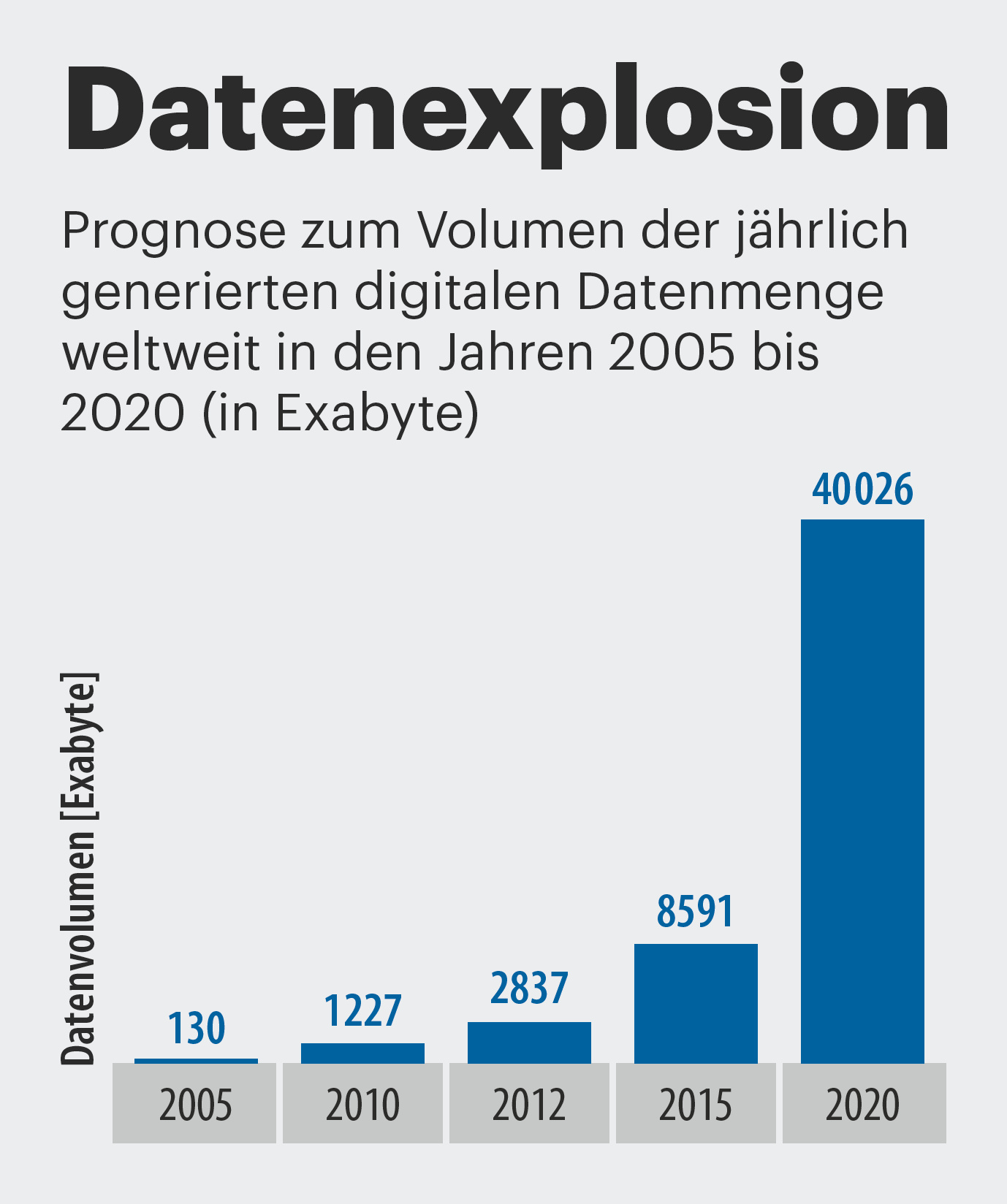
Die Menge der von einzelnen Personen hinterlassenen Daten wächst exponentiell. 90 Prozent aller durch Internet-Nutzung erzeugten Daten sind in den letzten zwei Jahren entstanden. Der Festplattenhersteller Seagate prognostiziert, dass die jährlich produzierte Menge von 3,5 Zettabyte im Jahr 2013 auf 40 Zettabyte im Jahr 2020 ansteigen wird. Ein Zettabyte sind eine Milliarde Terabyte.
Derzeit sammeln Konzerne und staatliche Behörden wie die NSA alles, was möglich ist. Vieles wird erst einmal unstrukturiert weggespeichert, weil noch Auswertungsmethoden oder Rechenpower fehlen. Eines ist aber sicher: Nie war transparenter, was wir im letzten Sommer getan haben. Und im Sommer davor. Und dazwischen.
Big Data bedeutet nicht nur, viele Daten zu sammeln und auszuwerten, sondern insbesondere auch, verschiedenste Datenquellen zu fusionieren. Führt ein sogenannter Data Scientist eigene Daten mit Fremddaten zusammen, spricht er von einer „Anreicherung“ – die Fusion führt zu einem Informationsgewinn: Ergänzt er etwa die E-Mail-Adresse einer Person um deren Postadresse oder gar Charaktereigenschaften, macht er die Daten für die Verwendung wertvoller. Deshalb erscheint es nur folgerichtig, dass um all unsere persönlichen Daten ein munteres Geschachere entstanden ist.
Big-Daten-Business
Viele dubiose, kleine Firmen bevölkern den Datenmarkt. Doch beherrscht wird er von großen, international agierenden Konzernen, wie zum Beispiel Acxiom, Datalogix, Rapleaf, Core Logic oder PeekYou. Acxiom, einer der Branchenriesen, erwirtschaftet weltweit mehr als eine Milliarde US-Dollar pro Jahr und verwaltet über 15.000 Datenbanken für seine über 7000 Kunden. Der Konzern verfügt über 700 Millionen aktive Konsumentenprofile, darunter mehr als 40 Millionen aus Deutschland.
Pro Haushalt listet Acxiom durchschnittlich 1500 Einzelangaben in seinen Datenbanken auf. In Deutschland teilt der Konzern die Bevölkerung – beruhend auf Alter, Familientyp und Sozialstatus – in 14 Hauptgruppen ein, etwa in „Alleinerziehend & statusarm“, „Midlife-Single & gut situiert“, „Goldener Ruhestand & aktiv“. Nach verschiedenen Lifestyle-Merkmalen erfolgt eine weitere Kategorisierung in über 200 Untergruppen. Darin unterscheidet Acxiom dann etwa Raucher von Nichtrauchern oder nach Vorlieben in den Bereichen Sport, Freizeit, Technik, Telekommunikation und Tourismus.
Acxiom bietet anderen Datensammlern an, ihre bereits existierenden Kundenprofile mit Informationen aus den Acxiom-eigenen Datenbanken anzureichern. Auf diese Weise können äußerst umfangreiche Persönlichkeitsprofile entstehen. Das Unternehmen agiert sehr abgeschirmt. Alarmieren sollten aber bereits die Aussagen im Firmenprospekt: Man verfüge über ein „einzigartiges Spektrum an Markt- und Konsumentendaten“ mit dem die Datenanreicherung und „präzise Qualifizierung nahezu jeder postalischen Anschrift in Deutschland“ möglich sei.
Der Konzern ist einer von wenigen Partnern, von denen sich selbst der Datenkrake Facebook noch Informationsgewinn verspricht. Facebook kauft für verschiedene Länder, darunter auch Deutschland, Acxiom-Datensätze zu. Das Ziel der 2015 gestarteten Kooperation: Die Facebook-Werbekunden sollen ihre Zielgruppen noch präziser als ohnehin schon abschöpfen können. Im Ad-Management-Tool von Facebook ist nun der Hinweis zu finden: „Acxiom Mikrotyp beinhaltet umfangreichste Zielgruppendaten und entspricht dem BDSG. Alle Daten sind statistische Schätzwerte und je nach Sensitivität auf Haus-, Mikrozell- (5 Haushalte) oder Straßenabschnittsebene aggregiert.“
Woher diese Informationen stammen? Auch hier lautet das Zauberwort „Datenfusion“: Acxiom kooperiert beispielsweise seit einigen Jahren mit ImmobilienScout24. Die dort gesammelten Informationen über vermietete und verkaufte Wohnungen und Häuser landen daher in den Datenbanken von Acxiom. Auf diese Weise bekommt der Datenhändler im Laufe der Zeit genaue Einblicke in die Wohnsituation der Menschen.