
Prozessorgeflüster
Von Epyc und EPIC
Kurz vor der Computex geht das Gerangel schon los. Da tauchen jedenfalls viele neue und auch ein paar recht betagte Namen auf: Epyc, Threadripper, Skylake-X, Kaby Lake-X, Core i9, Kittson, Vega, Volta …
Verwende bloß nicht Überschriften wie in „epyscher Breite“ oder gar „Epyc Fail“ – so die dringende Warnung eines Kollegen, um naheliegenden, aber sehr fragwürdigen Sprachspielen mit dem von AMD auf dem Financial Analyst Day bekanntgegebenen Namen der neuen Serverlinie vorzubeugen. Der Name Epyc, der nunmehr den Opteron ablöst, war so überraschend nicht, stand er doch schon seit einiger Zeit in AMDs Trademark-Liste des USPTO, genauso wie etwa Zenso, Aragon, Vara, Joro, Jitzu, Grok und Threadripper – da kann man jetzt gespannt sein, für welche Produkte diese Namen demnächst verwendet werden.
Von Threadripper weiß man’s inzwischen, denn das ist der eingetragene Name des von AMD nun offiziell bestätigten Sechzehnkerners für High-End-Desktop-PCs mit dem Sockel SP3r2. Er dürfte wohl auch unter diesem Label ins Rennen gehen und nicht etwa als Ryzen 9. Mehr dazu soll auf der Computex verraten werden. Vorgesehen ist das „Thread-Monster“ mit seinen 32 Threads und vier Speicherkanälen schon für den Sommer. Über den Takt wird noch spekuliert, so knapp über 3 GHz werden erwartet.
Core i9
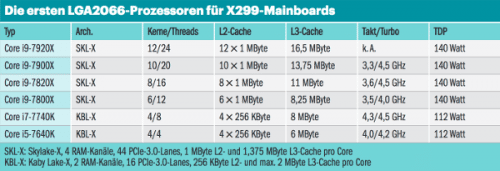
Intel will durchgesickerten Informationen zufolge gleich auf der Computex kontern und zwar mit dem Core i9 (Skylake X) mit bis zu zwölf Kernen (Core i9 7920X) für LGA 2066. Einige Websites wurden von Intel derweil gebeten, zumindest das „diskriminierende“ entschlüpfte Bild aus einer deutschen Intel-Präsentation wieder zu entfernen. Der Zwölfkerner mit noch unbekanntem Takt soll danach erst im August herauskommen, die anderen mit 10, 8 und 6 Kernen bereits im Juni. Der Zehnkerner I9-7900X steht dabei mit 3,3 GHz Basistakt und 4,3 GHz Turbo in der Liste. Als weiteres Pfund soll die Core-i9-Familie auch AVX512 bieten, aber möglicherweise etwas langsamer als beim Xeon, gegebenenfalls mit nur einer statt zwei FMA-Units. Man hörte im Umfeld zudem davon, dass auch beim Xeon die beiden Vektoreinheiten unterschiedlich angekoppelt seien, eine innere und eine weiter außen liegende, die dann einen Takt mehr Latenz aufweist. Das wird das Benchmarken dann noch etwas schwieriger machen.
Benchmarken ist aber ohnehin so eine Sache: AMD hat sich da bei der neuen Radeon Vega Frontier Edition (siehe S. 32) auch nicht grad mit Ruhm bekleckert, als man irgendwie eine DeepBench-Gesamtlaufzeit zusammenzimmerte. Aber letztlich ist ja nur die Aussage wichtig, dass AMD nun ein Produkt hat, das auch beim großen Trendthema Deep Learning mitmischen kann und das dafür auch natives fp16-Gleitkommaformat bietet. Okay, Nvidia wird mit den Tensor-Einheiten im Volta wieder einen großen Schritt voranschreiten – der Tensor Core erinnert mich ein bisschen an die damals „revolutionäre“ Matrix-Einheit (4×4-Matrix mal 4×1-Vektor) im 3C87-Coprozessor von IIT – für die Jüngeren: Früher war mal die FPU in einem eigenen Chip außerhalb der CPU untergebracht.
Letzter Mohikaner
Apropos erinnern: Mich erinnert obiger Name Epyc an eine andere, fast schon vergessene Servergeneration, nämlich an EPIC: Explicit Parallel Instruction Computing. So nannte sich die Architektur des Itanium-Prozessors, bei der bereits der Compiler die parallele Ausführung in verketteten Befehlsbündeln vorgab und wo nicht der Prozessor das erst zur Laufzeit jedes Mal aufs Neue mit zahlreichen Tricks wie Register Renaming und mit sehr aufwendiger Hardware erledigen musste. Auch auf eine komplexe Out-of-Order-Execution verzichtete Intel damals, das machte die Hardware noch weit einfacher, aber dafür opferte man nach den Simulationsergebnissen von Wissenschaftlern gut 40 Prozent Performance.
So richtig gut hat das EPIC-Konzept allerdings nie funktioniert, die zahlreichen Einschränkungen bei der Bündelung von Befehlen waren für den Compiler einfach zu komplex, auch wenn die Bündelregeln und die Compiler im Laufe der Zeit deutlich nachgebessert wurden. Geradezu lächerlich gemacht hatte sich die erste Itanium-Version Merced im Jahre 2001 mit ihrer x86-Emulation. Mit ihrer mehr als blamablen Performance konnte man nicht einmal einen Sysmark-Benchmark fahren, ohne dass er wegen Timeouts abbrach. Dabei sollte die x86-Performance nach den ursprünglichen Vorgaben mindestens im oberen Bereich der Desktop-Mittelklasse liegen. Aber durch den unerwartet heißen Konkurrenzkampf mit AMD gegen Ende der 90er Jahre explodierte auf diesem Kampffeld förmlich die Performance, die Desktop-x86-Prozessoren waren plötzlich um Größenordnungen voraus.
Mit seinen jeweils 128 Integer- und Gleitkommaregistern bot der Itanium jedoch zahlreiche Features, die andere Prozessoren bis heute nicht kennen – da konnte man einzelne Bits einschieben oder löschen, Gleitkommadivisionen latenz- oder durchsatzoptimiert einsetzen (mit nur 5 Takten bei DP) und viele solcher Dinge mehr. Zudem hatte man ein weitaus effizienteres Memory Management als x86 unter anderem mit wählbaren Page-Table-Formaten und mit elf Page-Größen zwischen 4 KByte und 4 GByte.
Letztlich war es auch gar nicht so sehr die Itanium-Hardware, sondern die nicht ausgereiften Compiler, die den Niedergang der EPIC-Idee verursachten, sie schafften einfach die nötige Parallelisierung nicht oder nur unzureichend. Nach den Untersuchungen von Wissenschaftlern von der australischen University of New South Wales konnte man jedoch mit Assembler und mühsamer Handoptimierung den Itanium zuweilen mit bis zu zehnfacher Performance gegenüber der Compiler-Version durchaus zum Fliegen bringen. Nur wer macht sich außer den Wissenschaftlern at work from a land down under so viel Mühe?
Ähnliches Schicksal mit zu komplexer Programmierung hatte einst schon Intels RISC-Prozessor i860 zu Fall gebracht. Es heißt, dass sich Microsoft-Programmierer weigerten, Windows NT für den i860 zu implementieren. Und Sonys Playstation-3-Programmierer kamen mit IBMs komplexen Cell offenbar auch nicht wirklich zurecht, sodass man lieber zum leichter handhabbaren vielkernigen x86-Prozessor (AMD Jaguar) wechselte.
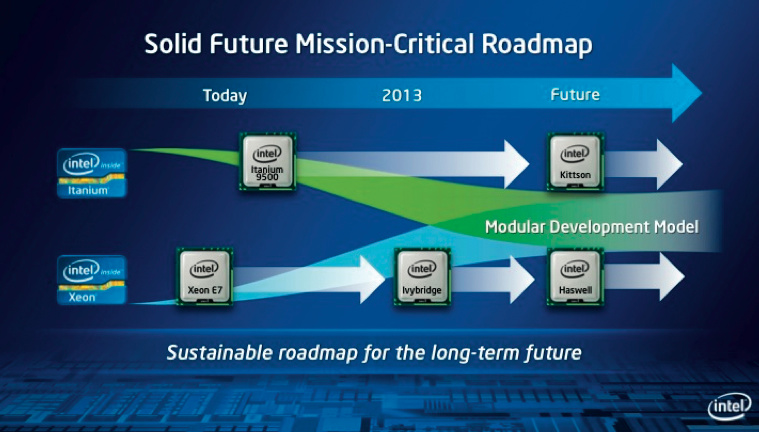
Itanium hat sich allerdings dank seiner enorm hohen Verfügbarkeit und vor allem durch die Verträge mit Hewlett Packard immerhin schon 16 Jahre lang gehalten. Allmählich jedoch ist seine Zeit abgelaufen; jetzt hat Intel den definitiv letzten Mohikaner Kittson (Chingachgook wäre wohl zu schwierig auszusprechen gewesen) mit vier und acht Kernen als Itanium 9700 mit bis zu 2,66 GHz Takt in die Prärie entlassen. Der hat allerdings kaum noch was mit dem ursprünglich mal geplanten Kittson zu tun, ist nur ein kleiner Aufguss des Poulson (Itanium 9500) und dient mit seinem betagten 32-nm-Prozess als Restnutzer für alte Fabs. Aber HPE hat seinen Kunden noch vollen Itanium-Support bis 2025 versprochen.
The Machine Prototype 2
Bis dahin soll HPEs anderes Projekt „The Machine“ wirklich Wirklichkeit sein. Der jetzt vorgestellte zweite Prototyp rund um den neuen ARM-Prozessor Cavium Thunder X2 – mit zunächst nur 32 der vorgesehenen 54 Kerne – ist noch in der Phase 1, vor allem fehlt weiterhin der nichtflüchtige Speicher. HPs einst für eine spätere Phase vorgesehenen Memristoren haben sich offenbar in Wohlgefallen aufgelöst, auf Intels 3D-Xpoint will HPE auch nicht unbedingt bauen und das gemeinsam mit Western Digital in der Entwicklung befindliche Storage Class Memory lässt noch auf sich warten. Dass das vorangeht, dafür sorgt seit Anfang des Jahres der „Vater“ der Machine, Martin Fink. Der war als CTO und Forschungsdirektor von HPE gegen Ende letzten Jahres in den Ruhestand getreten. Doch nach 3 Monaten „Rosen züchten“ kehrte er in die Szene zurück – als CTO bei Western Digital.
HPE hat jetzt einen Server mit 40 Thunder-X2-Knoten vorgestellt, mit bis zu 160 TByte DDR4-Speicher und mit dem von HPE entwickelten schnellen optischen Interconnect X1. Die Memory-driven-Architektur sieht dabei einen gemeinsamen Speicherraum vor, der von einer speziellen Linux-Version verwaltet wird.
Distributed Shared Memory (DSM) kennen andere Cluster allerdings auch und 160 TByte für 40 Knoten dürften technisch inzwischen ebenfalls machbar sein, das ist dann eher eine Frage des Geldbeutels. Mit sechs oder mehr Speicherkanälen aufwarten kann jedenfalls nicht nur der Cavium Thunder X2, sondern demnächst auch Intels Skylake SP, AMDs Epyc oder IBMs Power9. Was The Machine allerdings voraus hat, ist die besonders schnelle Anbindung der Knoten und des Speichers über die optischen X1-Links mit bis zu 1,2 TBit/s.
Apropos IBM Power9: Der 24-Kerner soll in der zweiten Jahreshälfte herauskommen, als eines der ersten Prozessoren mit PCIe-4 (16 GBit/s pro Lane). Insbesondere hat er auch über die noch schnellere BlueLink-Schnittstelle Anschluss via NVLink 2 an NVidias neue Volta-GPUs, die ebenfalls in der zweiten Jahreshälfte auf den Markt kommen sollen. Zwei bereits bestellte Supercomputer mit jeweils etwa 150 PFlops Zielperformance warten auf die beiden: Summit beim Oak Ridge National Lab und Sierra am Lawrence Livermore National Lab. Auch hierzulande will das Gespann um IBM, Nvidia und Mellanox bei den Ausschreibungen mitbieten, etwa bei den ganz Großen wie dem Jülicher Supercomputer Center und dem Leibniz-Rechenzentrum.
Europas schnellster Supercomputer, der Piz Daint am Schweizerischen Supercomputerzentrum in Lugano, wartet indes nicht auf Volta; er wurde ja auch erst in den letzten Monaten komplett mit Pascal-P100-GPUs aufgerüstet. Es sind noch mehr P100-Knoten geworden als die 4500, von denen im vergangenen Jahr die Rede war, als Piz Daint mit der Teilbestückung von 3050 P100-Karten und mit knapp 10 PFlops den Platz 8 in der Liste erreichte. Er ist jetzt deutlich schneller, wie schnell, darf ich noch nicht verraten – da muss man den ersten Tag der ISC17 abwarten. (as@ct.de)