
Prozessorgeflüster
Von Flagge halten und Flagge zeigen
Der Goldmont-Kern des neuen Atom-SoCs Apollo Lake bleibt mysteriös. Jetzt brachte Intel die IoT-Versionen E3900 heraus. FPGAs machen im HPC-Umfeld von sich reden, ARM64-Prozessoren dagegen weniger.
Nur wenige Tage nach den US-Wahlen will sich die internationale HPC-Community – falls sie dann überhaupt noch ins Land kommt – zur Supercomputer 2016 (SC16) in der Mormonen-Metropole Salt Lake City treffen. Das ist dort, wo man Bier und andere alkoholische Getränke nur als Beigabe zum Essen bekommt und wo man eine der in Köchern steckenden roten „Crosswalk flags“ tragen sollte, wenn man in der Innenstadt eine Hauptstraße überquert.
Neben dem Wahlausgang dürfte vor allem AMD als möglicher Phoenix aus der Asche auf der SC16 für Gesprächsstoff sorgen. Der AMD-Stand ist mit gerade mal 400 Quadratfuß zwar nicht gerade riesig, jedenfalls wenn man das mit den beiden Spitzenausstellern Nvidia (5000 sqft) oder Intel (4200 sqft) vergleicht, dürfte aber ausreichen, um den für HPC vorgesehenen Zen-Prozessor Naples mit viel Tamtam zu präsentieren. Mit seinen acht Speicherkanälen müsste er sich etwa bei dem speicherlastigen HPCG-Benchmark gut in Szene setzen. Optimisten hoffen zudem auf die erste Vorführung von AMDs nächster GPU-Generation Vega. Man hört auch von einem auf FPGAs beruhenden Applikationsbeschleuniger namens Magnum. Von AMDs ARM64-Engagement ist hingegen nicht viel zu hören.
Auch bei den meisten anderen ARM64-Vertretern ist es recht ruhig geworden, jedenfalls im Server- und HPC-Umfeld, auch wenn ARM auf der SC16 weiterhin einen Stand hat. Applied Micro ist dort jedoch verschwunden. Verabschiedet sich diese Firma mit ihren X-Gene-Prozessoren gar wieder von HPC? Neuerdings gibt es ja noch die chinesische Firma Phytium. Die konnte zwar auf der Hot-Chips-Konferenz im August erste Systeme mit dem speziell für HPC optimierten Mars-Prozessor vorführen – bleibt außerhalb Chinas aber immer noch recht unsichtbar.

Samsung ist derweil offenbar aus dem Rennen ganz ausgestiegen und hat den geplanten Server-Kern zu einem Mobile-Kern namens M1 umgewidmet. Den brachte man alternativ zum Snapdragon 820 im Exynos 8890 des Galaxy Note 7 unter. Mit diesem Smartphone hat Samsung derzeit bekanntlich recht große Sorgen – die ARM64-Kerne sollen daran aber unschuldig sein.
Qualcomm hat zwar ein paar neue Snapdragons für Smartphones herausgebracht, kommt mit dem 24-kernigen Server-Chip aber nicht in die Puschen. Okay, Qualcomm hat derzeit mit dem geplanten Aufkauf von NXP für geschätzt 37 Milliarden US-Dollar anderes um die Ohren. Konkurrent Avago hatte im vergangenen Jahr den gleichen Betrag für Broadcom berappt, aber auch von dort ist nichts zu sehen.
So ruhen die gesamten ARM64-Hoffnungen in dieser Szene auf der Firma Cavium und die ist auf der SC16 präsent. Systeme mit ihrem 48-Kern-Chip Thunder X kann man tatsächlich etwa von Gigabyte kaufen. Im Sommer auf der ISC16 bei der Student Cluster Competition waren zwei ThunderX-Systeme dabei, konnten aber nicht so brillieren. Das könnte jetzt zur SC16 mit dem im Sommer angekündigten 54-Kerner Thunder X2 anders werden, zumindest müsste der mit bis zu 3 GHz Takt im Turbo deutlich mehr Performance bieten.
Bei der anstehenden Student Cluster Competition gehen übrigens erstmals gleich zwei Teams aus Deutschland an den Start: die im vorigen Jahr im Linpack mit 7,13 TFlops siegreiche Technische Universität München mit dem Team PhiClub sowie die ebenfalls schon SC16-erfahrene Friedrich-Alexander-Universität Erlangen-Nürnberg mit dem Team segFAUlt.
FPGA kontra Xeon Phi
FPGAs werden für HPC offenbar ein immer wichtigeres Thema. Nallatech bietet schon seit geraumer Zeit eine Beschleunigerkarte mit Altera Arria 10 an. Der FPGA-Hersteller Altera wurde für gerade mal 16,7 Milliarden Dollar 2015 Jahr von Intel übernommen und so stehen FPGAs jetzt ganz prominent auf Intels SC16-Programm, neben Neuromorphic Computing, Machine Learning und dem Weg zu Exascale-Systemen. Schließlich ist der bei Intel in 14-nm-Technik hergestellte riesige Stratix 10 jetzt fertig und wird bemustert. Mit seinen vier Cortex-A53-ARM64-Kernen und bis zu 5,5 Millionen Logikzellen soll er 9,2 TFlops (GX/SX 2800) bei einfacher Genauigkeit erreichen und dabei weit energieeffizienter sein als die CPU/GPU-Konkurrenz. Mit vier über Intels neue Imposer-Technik EMIP angeschlossenen High Bandwidth Memory Stacks (HBM2) kommt der Stratix 10 auf über 1 TByte/s Speicherbandbreite – dagegen sieht Intels hausintere Konkurrenz Xeon Phi 7200 mit ihrem seriellen Hybrid Memory Cube (HMC) mit maximal 460 GBytes/s geradezu alt aus.
Da muss man wohl auf den Xeon Phi 8800 warten, wie die nächste Generation mit Codenamen Knights Hill mit ihren bis zu 88 Kernen vielleicht heißt. Der wird jedenfalls vom proprietären HMC zum JEDEC-Standard HBM2 wechseln – Erfahrung damit kann Intel ja nun schon beim Stratix 10 sammeln.
Auch wenn Intel für ARM64 im Stratix 10 die Werbetrommel rührt und demnächst bei 10 nm als ARM64-Auftragsfertiger fungieren wird, auf ARM Techcon direkt vor ihrer Haustür in Santa Clara stellte die Corporation noch nicht aus. Auf dieser Konferenz ging es vor allem um IoT und Embedded, doch zu just der gleichen Zeit fanden zu dem Thema zahlreiche Konkurrenzveranstaltungen statt, etwa die IoT Planet Trade Show in London oder den IoT Solutions World Congress in Barcelona.
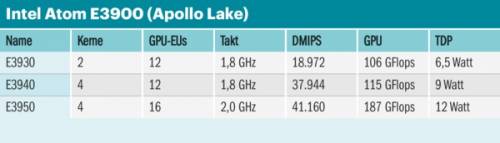
Hier wiederum ist Intel sehr aktiv und stellte den für diesen Markt gedachten Apollo Lake E3900 vor. Der kommt zunächst in drei Versionen zwischen 6,5 und 12 Watt TDP. Für Automotive wird es noch eine spezielle Version geben mit dem dort verlangten höheren Temperatur-Bereich. Kleinverbraucher wie der E3805 mit 3 Watt sind nicht dabei, aber wie Intels General Manager der IoT Group, Jonathan Luse, in einer vorab in München gehaltenen Pressekonferenz berichtete, kann die maximale Energieaufnahme je nach Applikation auch deutlich niedriger liegen.
Das E3900-SoC sieht den auf der IFA bereits vorgestellten Desktop-Kollegen sehr ähnlich, bietet bis zu 4 MIPI-CSI-Kamerakanäle und hat zusätzlich ein paar bei den Desktop-Versionen möglicherweise nicht freigeschaltete Features wie „Intel Time Coordinated Computing Technology“, das ein präzises Timing von unter 1 Mikrosekunde sicherstellen soll.

Zum neuen Atom-Kern Goldmont gibt es weiterhin nur vage Informationen, immerhin soll er bei SPECint_base 2006 (1 Thread) bis zu 70 Prozent schneller sein als der Vorgänger Silvermont aus der 3800-Familie. Bei gleichem Takt und Energieverbrauch beziffert Intel die Performancesteigerung (IPC) auf beeindruckende 49 Prozent. Da muss man an der Architektur ganz schön geschraubt haben. Hyper-Threading, wie etwa beim Atom-Derivat im Xeon Phi 7200, hat er nach Aussage von Luse jedoch nicht.
Bei der 3D-Grafik sieht der Performancesprung dank der 18 Gen-9-Ausführungseinheiten noch markanter aus, das geht hoch bis hin zum Faktor 2,9 (3DMark 11), was ruckelfreies 4K mit 60 Hz ermöglicht. Unter Windows setzt das allerdings Version 10 voraus, denn nur dafür gibt es Grafik-Treiber.
Dumm nur, dass in der Embedded-Welt fast ausnahmslos Windows 7 oder 8 eingesetzt wird. Darauf Luse: Die alten Betriebssysteme könnten die neuen Prozessorfeatures nicht voll oder gar nicht ausnutzen. Dennoch habe man auch ein Budget für Betriebssysteme der letzten oder vorletzten Generation, warte aber zunächst eine entsprechende Nachfrage ab. Ein bisschen vom Treiber-Budget sollte Intel dann vielleicht auch für den OpenGL-Nachfolger Vulcan einplanen, denn bislang ist nur OpenGL 4.2 vorgesehen. (as@ct.de)