

Warten auf den Erlkönig
Superrechner: Die 53. Top500-Liste und viele neue Projekte
AMDs kommender Rome-Epyc, aber auch Quantencomputer und vor allem KI-Techniken sind heiße Themen der Supercomputer-Szene – und für einen Top500-Platz braucht man jetzt über 1 Billiarde Rechenoperationen pro Sekunde.
Wohin man auch kam, AMDs „Rome“ war der klar dominierende Prozessor auf der Supercomputing-Konferenz ISC’19 in Frankfurt – dabei gibt es ihn noch gar nicht. Er wurde auch nur in verschlossenen NDA-Räumen gezeigt, lugte aber irgendwie überall heraus. Allerorten hieß es: Intel muss sich warm anziehen. Im Besprechungsraum von Cray sah man sich von AMD-Logos geradezu überflutet. Schließlich baut Cray den Exascale-Rechner Frontier am Oak Ridge National Lab (ORNL) mit AMD-Prozessoren (dann schon Milan) auf, der 2021 mit 1,5 Exaflops (EFlops) brillieren soll. Oak Ridge will auch AMDs Radeon Instinct als GPU-Beschleuniger einsetzen und bekam vom US-Energieministerium DOE einen Riesenetat für Softwareentwicklung. Das lässt hoffen, dass dadurch dann endlich auch ein vernünftiger Softwarestack fürs High-Performance-Computing (HPC) mit Radeons kommt.
Viele große deutsche Rechenzentren haben sich ebenfalls schon auf AMD „eingeschossen“: Prof. Michael Resch, Chef vom HLR Stuttgart, freute sich sichtlich auf „Hawk“, der bis Ende 2019 mit einer theoretischen Rechenleistung von 24 PFlops die Spitzenposition in Deutschland oder gar in Europa übernehmen könnte.
Auch Prof. Thomas Lippert, Leiter des Jülicher SC, verriet im Gespräch, dass man sich beim Booster 2 für Rome entschieden habe. Dazu kommen jede Menge GPUs, aber wohl Nvidia Tesla statt Radeon Instinct. Da wäre es natürlich gut, wenn auch Nvidia auf PCIe 4.0 hochrüsten würde – das gilt jedoch für die kommende Ampere-Generation als sicher.
Auch bei den noch laufenden Ausschreibungen etlicher anderer Rechenzentren liegt AMDs Erlkönig sehr gut im Rennen. Analysten wie Addison Snell erwarten für AMD und ARM schon in naher Zeit 20 bis 25 Prozent Marktanteil im HPC-Markt.
An Intels Xeons festhalten dürfte jedoch das Leibniz-Rechenzentrum (LRZ) in Garching: Der nächste SuperMUC wird vermutlich eine kleinere Ausführung des für 2021 geplanten Exaflops-Rechners Aurora am Argonne National Lab sein, mit dem das LRZ eng kooperiert. Zu Aurora gab Intels HPC-Chef Hazra weitere Eckdaten bekannt: Er bestätigte den Einsatz der kommenden Xe-GPUs als Beschleuniger und versprach mehr als 10 PByte Hauptspeicher und 230 PByte Massenspeicher. Das parallel angebundene (Open-Source-)Filesystem Distributed Asynchron Objectoriented Storage (DAOS) ist für SSDs optimiert und soll Daten mit insgesamt 25 TByte/s übertragen.
Top500
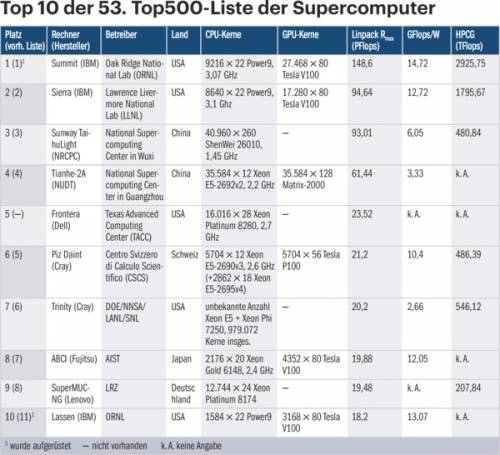
94 Systeme sind neu in die 53. Top500-Liste eingezogen, alle bis auf eines mit Intel-Prozessoren bestückt. Die Ausnahme stellt das französische Power9-System Pangea III da, das beschleunigt mit Nvidia Tesla V100 mit 17,8 PFlops Platz 11 erklimmt. Immerhin in acht der neuen Rechner laufen Intels neue „Cascade Lake“-Xeons. Das „langsamste“ Top500-System – mit älteren Broadwell-Xeons (60.000 Kerne), aber ohne Beschleuniger – bringt es nun auf 1,022 Petaflops (PFlops). Doch insgesamt wuchs die Gesamtperformance der Top500-Liste lediglich um 10 Prozent auf 1,56 EFlops, relativ gesehen der zweitschwächste Zuwachs in der über 25-jährigen Geschichte der Liste überhaupt.

Ein Überraschungssystem mit AMD Rome war nicht in der neuen Top500-Liste verzeichnet, auch kein weiteres ARM-System außer HPEs Astra. Das dürfte sich in den nächsten Jahren deutlich ändern, die Sandia Labs wollen in ihrem Vanguard-Projekt einen weitaus leistungsfähigeren Astra-Nachfolger aufbauen und Europa will Ende 2020 mit dem Mare Nostrum 5 in Barcelona Flagge zeigen.
Angeführt wird die Top500-Liste weiterhin vom amerikanischen Summit mit Power9/Nvidia Tesla V100 am ORNL. Er hat seit November 2018 noch ein paar Racks hinzubekommen und verfügt nun über 2,4 Millionen Kerne: 2,2 Millionen Nvidia Streaming Cores, der Rest Power9-Kerne. Platz 2 hält wie gehabt sein kleinerer Power9-Kollege am Lawrence Livermore National Laboratory (LLNL) mit 94,6 PFlops. Auch Platz 3 und 4 sind gleich geblieben: die beiden chinesischen Systeme Sunway TaihuLight mit 93 und Tianhe-2A mit 61,4 PFlops.
Dann aber folgt auf Platz 5 ein Neuling: der Frontera am Texas Advanced Computing Center (TACC) in Austin. Das im Aufmacherbild gezeigte Dell-C4130-System kommt ohne Beschleuniger mit 448.448 Xeon-Cascade-Lake-Kernen auf 23,5 PFlops und darf sich damit schnellster „Universalrechner“ nennen, vor dem SuperMUC-NG in München, der mit 19,5 PFlops Platz 9 belegt.
Der Trend hin zu Beschleunigern hat sich etwas abgeschwächt. Intel hat den Xeon Phi eingestellt und den Xe erst für 2020 avisiert und Nvidia musste einen, allerdings nur leichten, Verlust in Kauf nehmen: 125 der 500 Top-Systeme sind mit Nvidia-GPUs bestückt, zuvor waren es noch 127. Nvidia hatte jahrelang den größten Stand auf der ISC, verzichtete aber diesmal darauf und nassauerte im Marriott-Hotel nebenan. Lustigerweise hatte aber die Firma ARM (die fairerweise einen Stand auf der ISC buchte) die Marriott-Räume namens Volt und Ampere schon belegt – eine Anspielung auf Nvidia-Codenamen. Trotzdem hatte Nvidia für ARM eine wichtige Neuigkeit parat: Der komplette (CUDA-)Softwarestack für über 600 HPC-Applikationen soll nun auch für ARM bereitgestellt werden.
HPC-Altmeister Jack Dongarra zeigte mit Versuchen auf dem Top500-Spitzenreiter Summit, dass sich die Linpack-Performance durch den Einsatz von „Mixed Precision“-Algorithmen verdreifachen lässt – bei letztlich gleicher Genauigkeit. Das ist zwar für die Top500-Liste nicht erlaubt, aber wichtig für KI-Anwendungen, für die viele der kommenden Supercomputer ausgelegt werden – eine ähnliche Idee steckt ja auch hinter den VNNI- beziehungsweise DL-Boost-Befehlen in neuen Intel-Chips.
Deutschland schwächelt
Aus Deutschland hat es nur ein einziges neues System in die Top500 geschafft: der CLAIX an der Universität Aachen, der sich bei den reinen Unirechnern mit 2,5 PFlops auf Platz 92 und damit vor den – ebenfalls von NEC aufgebauten – Mogon II der Johannes-Gutenberg-Uni in Mainz schiebt (2 PFlops, Platz 131). Weiterhin klar die deutsche beziehungsweise bayrische Spitze markiert der schon erwähnte SuperMUC-NG weit vor dem Juwels Module 1 am Jülicher SC mit 6,2 PFlops.
Insgesamt ist Deutschland ziemlich abgefallen: Hatte man vor einem halben Jahr noch 17 Systeme mit 60,5 PFlops platziert, sind es jetzt nur noch 14 mit 59,1 PFlops. In der Top500-Liste steht dabei sogar noch der alte SuperMUC Phase 1, der längst deinstalliert ist. So liegt Deutschland stückzahlmäßig jetzt gleichauf mit Irland oder den Niederlanden. Unsere Nachbarn haben nämlich kräftig aufgerüstet, ihre Supercomputerleistung hat sich gegenüber der vorigen Liste mehr als verdoppelt. Frankreich übernimmt in Europa mit 19 Systemen und 67,1 PFlops die Führung, Großbritannien hat 18 Systeme mit 40 PFlops und Italien nur 5 Systeme, dafür recht kräftige mit zusammen 30 PFlops. Der schnellste europäische Supercomputer bleibt weiterhin der schweizerische Piz Daint (Cray XC50, Nvidia P100) am CSCS in Lugano mit 21,2 PFlops.
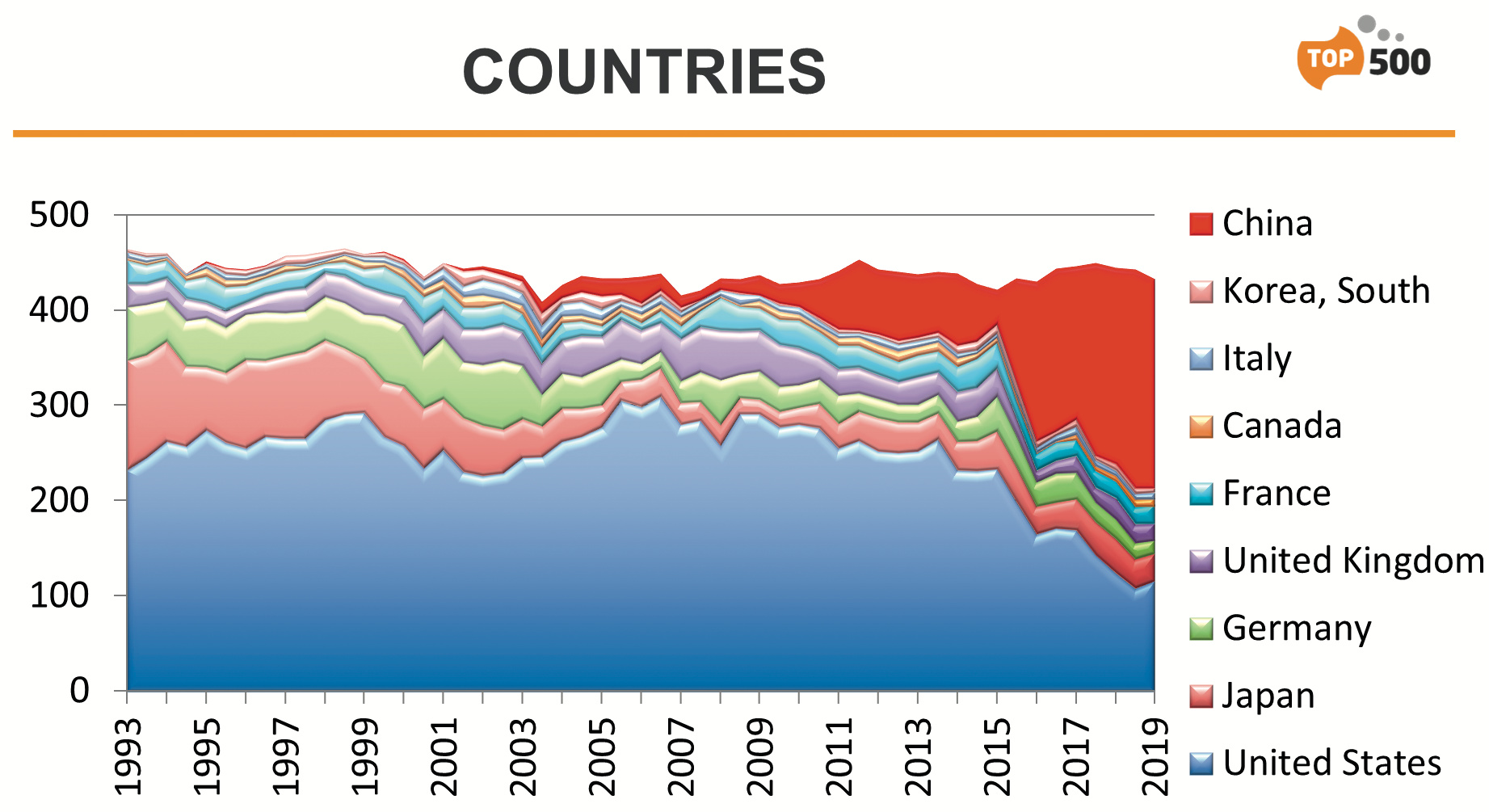
Weltweit hat China mit 219 Systemen (zuvor 229) etwas an die USA (119, zuvor 108) verloren, aber weiterhin fast doppelt so viele Systeme in der Liste. Die amerikanischen Systeme haben dank der beiden Spitzenreiter allerdings deutlich mehr Power, sie kommen zusammen auf 600 PFlops, die chinesischen „nur“ auf 466. Angeblich hat China wegen der aktuell heiklen politischen Lage jedoch ein neues 200-PFlops-System gar nicht erst für die Top500-Liste gemeldet. Es soll sich um eines der EFlops-Vorläufersysteme handeln, nämlich jenes mit AMD-Technik (Sugon/Dawning/Hygon Dhyana). Im kontinentalen Vergleich blieb die Verteilung der Rechenpower weitgehend gleich: Asien führt mit 42,8 Prozent vor Amerika (inklusive Kanada und Brasilien) mit 38,6 Prozent und Europa mit 18 Prozent.
HPE mit Cray-Power
Hieß es beim letzten Mal noch „HPE fällt zurück“, so hat HPE vor, das durch einen Trick zu kompensieren: Man hat sich im letzten Monat mit Cray über eine Übernahme geeinigt, nun müssen nur noch die Aufsichtsbehörden in den USA und Europa zustimmen. Solche Übernahmen haben bei HP ja Tradition: SGI 2016, Compaq 2002, Convex 1995, Apollo 1989 …
Die alte HPE fiel zwar von 45 auf 40 Systeme weiter zurück, kann (demnächst) aber 39 Cray-Systeme hinzubuchen. Und die haben es bekanntlich in sich. Mit der gemeinsamen Power von 316 PFlops liegt HPE/Cray damit vor dem mit 173 Systemen (zuvor 142) zwar stückzahlmäßig weit vorausliegenden Konkurrenten Lenovo, aber deren Gesamtleistung beträgt nur 306 PFlops. HPE und Lenovo müssen sich jedoch dank der beiden Spitzensysteme Summit und Sierra IBM geschlagen geben: nur 13 Systeme, aber 321 PFlops.
Intel hat noch ein bisschen zugelegt: In 478 Systemen (zuvor 476) stecken Xeons. Neben dem einzigen AMD-Epyc-System aus chinesischer Produktion findet man noch zwei alte Opteron-Systeme sowie eines mit ARM Cavium Thunder 2, den chinesischen Sunway TaihuLight mit hausgemachten ShenWei-Prozessoren sowie sechs japanische Sparc-Systeme und 13 mit Power/PowerPC.
Das Top500-Team verwaltet inzwischen auch die Resultate für die Energieeffizienz (Green500) und die vom HPCG-Benchmark, der sich weit stärker an der Speicherperformance orientiert als der für die Top500 zuständige Linpack. Doch hier hat sich gegenüber November 2018 fast nichts getan: Die mittlere Energieeffizienz beim Linpack ist von 3,0 GFlops/Watt auf 3,2 GFlops/Watt gestiegen.
Quanten-Nachwuchs
Europa und insbesondere auch Deutschland investieren erheblich in die Quantum Flagship Initiative für Quantencomputer, zum Teil führend. Am ersten geplanten europäischen Standort der Initiative, dem Jülicher SC, will man quasi alles einkaufen, was schon zur Verfügung steht, sowohl universelle Quantencomputer als auch Quantenannealer von D-Wave (siehe c’t 13/2019, S. 142). Die häufig geübte Kritik an der Annealer-Technik lässt Prof. Lippert nicht gelten: Klar gebe es Einschränkungen, aber dennoch handle es sich um echte Quantenmechanik. In etwa fünf Jahren, so IBMs HPC-Chef Dave Turek, werden Wissenschaftler universelle Quantencomputer mit einigen hundert Qubits produktiv einsetzen.

Und wie man mit Quanten-Annealern erfolgreich umgeht, das bewiesen drei 14- bis 16-jährige Domspatzen aus Regensburg. Die können nicht nur singen oder Trompete blasen, sondern sie berichteten in der gut besuchten Quanten-Flaggschiff-Session mit heller Stimme und in perfektem Englisch, wie sie erfolgreich das N-Damen-Problem für den D-Wave-Annealer aufbereitet haben – zunächst für ein 4-×-4-Feld. Die sogenannte Kostenmatrix konnten sie mit Vermittlung ihres Lehrers und der Jülicher Professorin Kristel Michielsen auf dem D-Wave 2000Q in Kanada laufen lassen. Dafür bekamen sie schon den 1. Preis bei Jugend forscht in Bayern und den 4. bundesweit.
Die Undergraduate Students in der Student Cluster Challenge waren schon etwas älter. 14 Teams sind inzwischen dabei, um HPC-Applikationen bei einem auf 3 Kilowatt beschränkten Leistungsbudget zum Fliegen zu bringen. Die Teams aus Barcelona mit Marvel/Cavium Thunder2 sowie aus Hamburg und Warschau mit dem NEC-Vektorrechner Aurora Tsubasa hatten jedoch von vornherein keine Chance gegen die anderen Teams, die mit reichlich Nvidia-Volta-Power und bewährtem Softwarestack ins Rennen gingen. Der Vorjahressieger, das Team aus Peking von der Tsinghua-Universität wurde diesmal vom Hauptkonkurrentem geschlagen: Nunmehr schon zum vierten Mal gewann ein Team vom CHPC in Südafrika. (ciw@ct.de)