

America first again
Die 51. Top500-Liste der schnellsten Supercomputer
Die USA liegen wieder vorne: Die Superrechner Summit und Sierra bringen es mit IBM Power9 und Nvidia Tesla V100 auf bis zu 122 Petaflops. Doch China entwickelt schon den Tianhe-3: Bei Supercomputern geht es nicht nur um Wissenschaft, sondern auch um Rüstung. Und in Europa stehen mittlerweile 101 der 500 schnellsten Computer der Welt.
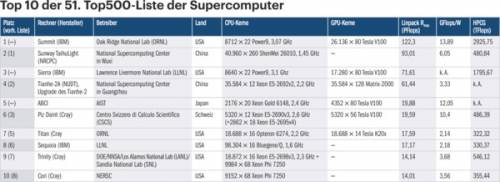
Den Wettkampf der schnellsten Supercomputer haben die USA nun für sich entschieden und auch den dritten Platz erobert. Die chinesischen Systeme Sunway TaihuLight und Tianhe-2A fallen auf die Ränge 2 und 4. Der amerikanische Vorsprung beim High-Performance Computing (HPC), das außer der zivilen Forschung vor allem auch Rüstungsprojekten dient, hält aber vielleicht nur bis 2019: In China wird der Tianhe-3 aufgebaut. Schon eines seiner Teilmodule könnte dann wieder den Top500-Spitzenplatz erklimmen.
Allerdings spricht manches dafür, dass die US-Systeme Summit und Sierra flexibler nutzbar sind als etwa der TaihuLight. Denn letzterer glänzt zwar im Linpack-Benchmark, der den Top500-Rang bestimmt, liegt aber im HPCG-Benchmark weit hinter den Konkurrenten. Und die Tensor-Einheiten der über 26.000 Nvidia-Tesla-Chips des Summit bringen es bei „Mixed Precision“-Berechnungen, die für KI-Anwendungen wichtig sind, theoretisch sogar auf mehr als 3 Exaflops, praktisch auf immerhin rund 1,5 EFlops.
Top Ten
Summit und Sierra kombinieren in jedem ihrer Cluster-Knoten jeweils zwei IBM-Power9-Prozessoren mit sechs beziehungsweise vier Nvidia-Tesla-Karten vom Typ V100, also mit Volta-Chips und je 32 GByte schnellem HBM2-Speicher. Diese GPU-Rechenbeschleuniger sind dabei nicht per PCI Express angebunden, obwohl der Power9 sogar PCIe 4.0 beherrscht, sondern per NVLink2.
Der japanische ABCI auf Platz 5 bringt es auf 19,88 PFlops, das ist weniger als ein Drittel des viertplatzierten Tianhe-2A. ABCI liegt nur hauchdünn vor dem schnellsten europäischen Rechner, dem schweizerischen Piz Daint mit Tesla P100 und 19,59 PFlops. Auf die restlichen vier Top-Ten-Plätze wurden ältere Rechner an US-amerikanischen Nationallabors verdrängt.
China, USA und Europa
Auch wenn die USA nun sechs der zehn schnellsten Rechner stellen, so fallen sie doch bei der Anzahl der gesamten Top500-Systeme weiter zurück. In China stehen jetzt 206 davon (zuvor 202), in den USA noch 124 (143). Japan folgt mit 36 (35), dann Großbritannien (22/15), Deutschland (21/22) und Frankreich (18/18). Europa hat nun 101 Top500-Supercomputer, acht mehr als zuvor.
Deutschlands schnellster steht jetzt wieder in Jülich: Juwels Modul 1 kommt mit 6,2 PFlops auf Platz 23 und verdrängt das Cray-System Hazel Hen im HLR Stuttgart. Juwels schafft zwar nur wenig mehr als schon der inzwischen entsorgte Bluegene-Rechner Juqueen (5 PFlops). Doch Juwels Modul 1 ist effizienter und flexibler einsetzbar, denn der Atos Bull Sequana kommt ohne Beschleuniger aus, darin stecken nur Xeon Platinum 8168. Und später kommt noch ein Booster hinzu, der die Performance vervielfacht.
Mit im deutschen Spitzenbereich eingemischt hat sich die Max-Planck-Gesellschaft mit Cobra, der bestückt mit Intel Xeon Gold 6148 ohne Beschleuniger auf 5,6 PFlops kommt und damit Platz 28 belegt. Schnellster klassischer deutscher Uni-Rechner ist mit 1,96 PFlops der Mogon II an der Johannes-Gutenberg-Universität Mainz, der erst im April offiziell eingeweiht wurde. Unterdessen entsteht in Garching der SuperMUC-NG, der über 20 PFlops liefern soll.
Industrie-HPC
Die meisten Systeme der Liste (279) sind unbenannte Supercomputer in der Industrie, traditionell viele von HPE, inzwischen aber vor allem von Lenovo. Lenovo verkaufte zum Beispiel gleich 26 neue C1040-Systeme mit je 1,649 PFlops, welche die Plätze 105 bis 130 belegen. Man erfährt darüber nur, in welcher Branche der jeweilige Käufer tätig ist. So führt nun Lenovo mit 120 Systemen (zuvor 79) weit vor HPE (79, zuvor 122), Inspur (68/56), Cray (56/53) und Sugon (55/51). HPE hat allerdings weniger identische Konfigurationen für die Top500 angemeldet – es gibt eine gewisse Dunkelziffer.
Insgesamt sind jedenfalls 132 Systeme neu in die Liste eingezogen. Die Mindestleistung dafür liegt jetzt bei 716 TFlops, im November 2017 reichten noch 549 TFlops (0,549 PFlops). Vor allem dank der neuen Spitzensysteme stieg die Gesamtleistung aller Systeme in der Top500 um kräftige 42 Prozent auf 1,2 Exaflops – gemeinsam haben sie also die Exascale-Marke schon übertroffen.
Im Schnitt dauerte es bislang jeweils etwa drei Jahre, bis ein einzelnes Spitzensystem die Gesamtleistung der Top500 in sich vereinte. Das deckt sich mit den Plänen in China, in den USA und in der EU, in den 2020er Jahren erste „Exascale“-Supercomputer aufzubauen. Die konkurrierenden Nationen investieren dafür jeweils Milliardensummen, die EU etwa im Rahmen des Projekts EuroHPC [1].
Effiziente Exoten
Für das Exascale-Rennen müssen Supercomputer beziehungsweise ihre Komponenten – Prozessoren, Rechenbeschleuniger, Infiniband-Vernetzung, Kühlsysteme – noch viel effizienter werden, also mehr Flops pro Watt liefern. Konkrete Daten verrät die Green500-Liste. Hier schlagen sich Nvidias jüngste Tesla-Beschleuniger V100 und P100 gut: Damit bestückte Superrechner belegen sieben der ersten zehn Green500-Plätze. Die ersten drei gehen jedoch an die japanischen Rechner Shoubu System B, Suiren2 und Sakura, in denen spezielle PEZY-SC2-Chips rechnen (ZettaScaler-2.2). Zusätzlich kommen Tricks wie Immersionskühlung zum Einsatz: Die Karten des Shoubu baden in der inerten Kühlflüssigkeit 3M Novec.
Mehr Superrechner arbeiten freilich mit (Warm-)Wasserkühlung, wie sie beispielsweise der SuperMUC in Garching (Platz 57) von IBM schon seit 2012 hat. IBM verwendet bei der neuen Nummer 1, dem Summit, ebenfalls direkte Wasserkühlung der Prozessoren und Tesla-Beschleuniger. Und auch Fujitsu wird es so halten beim kommenden Post-K-Superrechner, der ab 2020 am japanischen Riken entstehen wird.

In Frankfurt zeigte Fujitsu schon Prototypen der für Post-K vorgesehenen ARMv8-Prozessoren mit den neuen Scalable Vector Extensions (SVE), die 512-Bit-SIMD-Operationen ausführen. Ähnliche Technik will auch die European Processor Initiative (EPI) für EuroHPC-Computer umsetzen; zusätzlich sind noch KI-Beschleuniger mit RISC-V-Technik geplant.
Selbst entwickelte Rechenchips namens Matrix-2000 sitzen wiederum im chinesischen Tianhe-2A, der damit erheblich auf- und umgerüstet wurde. Hier kamen zuvor Intels Xeon-Phi-Rechenkarten zum Einsatz, die keine Zukunft mehr haben. Eigentlich war für dieses Jahr nämlich der CORAL am Argonne National Lab mit aktuellen Xeon Phis geplant, doch nun soll 2021 stattdessen ein Exascale-System mit dann neuen 10-Nanometer-Xeons kommen. Die chinesische Universität für Verteidigungstechnik arbeitet unterdessen am Matrix-3000, der mit 512 Kernen und 8 TFlops die vierfache Rechenleistung des Matrix-2000 liefern soll und mehr als 40 GFlops/Watt. Einen Matrix-2000+ gibt es schon: Anders als der Matrix-2000 bootet er selbst und braucht keinen zusätzlichen Hostprozessor.
Die Neulinge AMD Epyc und (Marvell) Cavium ThunderX2 spielen in der aktuellen Top500-Liste noch keine Rolle. Unter anderem Cray bietet aber Epyc-Einschübe für seinen CS500-Cluster an und hat auch schon mehrere ThunderX2-Rechner an Forschungseinrichtungen ausgeliefert. Aus Apollo-70-Systemen von HPE mit ThunderX2 wird derzeit am Sandia National Laboratory der Astra-Superrechner aufgebaut, der es mit 2,3 PFlops theoretischer Rechenleistung (RPeak) unter die Top-100 der aktuellen Liste schaffen könnte. Doch am Sandia-Labor will man nun erst einmal testen, wie viel der theoretischen ARMv8-Rechenleistung sich mit aktuellen Compilern im Linpack und mit anderen Algorithmen überhaupt ausschöpfen lässt. Der chinesische Hersteller Dawning (Marke: Sugon) will, wie zu hören war, mit AMD für ein kommendes Exascale-System kooperieren.

Rüstungsforschung
Beim HPC-Wettstreit zwischen den USA und China geht es auch um die globale Vormachtstellung bei der Rüstungsforschung. Die Kontrahenten päppeln dabei mit Fördermitteln nationale Zulieferer kritischer Komponenten. Einerseits will man den Gegner nicht mit High-End-Technik unterstützten, andererseits sorgt man sich um geheime Hintertüren in zugekauften Chips. In den USA hat etwa Globalfoundries zwei „Trusted Foundries“ von IBM übernommen und bringt auch die 14-nm-Fertigung in dieses Militärprogramm ein. Auch Frankreich als Atommacht fördert lokale Unternehmen wie Atos Bull.
Die USA schneiden feindliche Staaten von Produkten ab, falls diese für die Rüstungsforschung eingesetzt werden. Das traf 2015 den Tianhe-2 der Universität für Verteidigungstechnik der chinesischen Volksbefreiungsarmee (National University of Defense Technology, NUDT): Intel durfte die nächste Xeon-Phi-Generation nicht dorthin ausliefern. Deshalb hat die NUDT in kurzer Zeit den Matrix-2000 als PCIe-3.0-Rechenbeschleuniger entwickelt, wie ein Report von Professor Jack Dongarra erklärt, Linpack-Entwickler und HPC-Experte am Oak Ridge National Laboratory (ORNL).
Die ShenWei-Prozessoren des Sunway TaihuLight wurden in China entwickelt. In Kooperation mit Qualcomm arbeitet eine chinesische Firma am StarDragon mit 64-Bit-ARM-Technik. Um den chinesischen Phytium FT-2000/64 ist es hingegen recht still geworden.
Das Gebaren von Donald Trump im Handelsstreit mit China, Europa und sogar Kanada schürt auch in der europäischen Politik Ängste, von US-Spitzentechnik abgeschnitten zu werden. Das ist eine der Triebfedern hinter dem erwähnten EuroHPC-Projekt [1]. Der Brexit sorgt hier für weitere Unsicherheit. Dabei fällt auch auf, dass die britischen Prozessorexperten von ARM mittlerweile von SoftBank aus Japan übernommen wurden – und das japanischen Riken-Institut setzt nun eben auf ARMv8 mit SVE statt auf die US-amerikanische SPARC-Technik. Dafür gibt es allerdings vor allem wohl technische Gründe. (ciw@ct.de)