Babylon byteweisevon Herbert Braun in c't 9/06
Zurück zu heb@ct
Lange vor den Computern hatte die Telegrafie das Problem, Texte in Signale umzuwandeln. Die ersten optischen Telegrafen entstanden um 1800 und beschleunigte die Kommunikation gegenüber Pferdeboten dramatisch. Claude Chappe erfand die Semaphoren, die Napoleon bei seinen Feldzügen halfen. Mit zwei Signalstangen und zwei Querbalken auf kleinen Türmen ließen sich 196 verschiedene Zeichen quer durch das Land übertragen. Weiterentwicklungen wie die von Barnard Watson oder Niclas Edelcrantz schafften noch mehr; Pistors Balkentelegrafenlinie zwischen Berlin und Koblenz (1833/34) brachte es auf 4096 Zeichen.
Zu dieser Zeit mühten sich bereits mehrere Erfinder an elektrischer Telegrafie; den Durchbruch erzielte Samuel Morse 1837. Geschwindigkeit und Zuverlässigkeit der Übertragung waren den optischen Balkentelegrafen weit überlegen. Allerdings musste man nun Buchstaben, Ziffern und Satzzeichen in Abfolgen von elektrischen Impulsen auflösen.
Nach ersten Versuchen mit umfangreichen Code-Büchern erfand Morses Assistent Alfred Vail 1844 das Morsealphabet. Es sollte für Menschen leicht einzugeben und zu verstehen sein – eine Aufgabe, die es vereinzelt noch heute erfüllt; erst 2004 ergänzte man das Morsealphabet um ein Zeichen für @.
Mit seinen unterschiedlich langen Zeichen und Pausen eignet sich das Morsealphabet nicht für Maschinen. Als man um 1900 Zeigertelegrafen, Fernschreiber und Telex-Geräte baute, die lesbaren Text statt Morse-Gepiepe ausgaben, griff man auf eine andere Kodierung zurück: Émile Baudots bahnbrechende Kodierung von 1874, die Texte als Folge von fünf Binärziffern abbildete – also ein 5-Bit-Zeichensatz. Die 32 möglichen Signale musste der Versender mit den Kombinationen aus fünf Tasten einhändig eingeben.
Anders als das 30 Jahre ältere Morsealphabet ließ sich Baudots Code gut von Maschinen verarbeiten. Nach Weiterentwicklungen von Donald Murray (1901) und der Western Union war er als International Telegraph Alphabet No. 2 (ITA2) den größeren Teil des 20. Jahrhunderts über im Gebrauch.
Von den 32 Zeichen belegt das lateinische Alphabet bereits 26. Um den Vorrat zu vergrößern, nehmen diese 26 Zeichen nach Absenden des FIGS-Zeichens alternative Bedeutungen als Ziffern, Sonder- und Steuerzeichen an; LTRS schaltet zu den Buchstaben zurück. Einige der noch heute bekannten Steuerzeichen wie Wagenrücklauf (Carriage Return CR), Zeilenvorschub (Linefeed LF), Alarmzeichen BEL Nullbyte NUL (zum Testen der Verbindung) und Löschzeichen DEL sind mit ITA2 darstellbar. Mit einigen Doppelungen und nicht belegten Zeichen entstand so ein Vorrat von 53 Zeichen.
Übrigens gab es auch damals schon Probleme mit Internationalisierung: Russische Varianten erweiterten ITA2 um einen dritten Modus für kyrillische Lettern, der sich durch das Nullbyte zuschalten ließ.
Auch die ersten Computer nutzten ITA2 oder das verwandte U.S. TTY – schließlich gab es nichts anderes, und Computer wurden sowieso nur für Berechnungen benötigt. Erst das 1957 von der US-Armee entwickelte Kommunikationssystem Fieldata machte das Umschalten zwischen Zeichentabellen überflüssig: Mit 6 Bit bot es Platz für 26 Buchstaben, 10 Ziffern und 28 Sonderzeichen. Ein siebtes Bit ergänzte Steuerzeichen, die vor allem die Verbindungsdetails klärten, und brachte ein Alphabet für Kleinbuchstaben mit. Das kurzlebige System mit seinen zahlreichen Varianten gilt als direkter Vorläufer von ASCII.
1967 einigten sich Computer- und TK-Experten unter dem Dach der US-amerikanischen Standardisierungsorganisation ASA (der heutigen ANSI) auf die 7-Bit-Zeichenkodierung American Standard Code for Information Interchange – ASCII, auch bekannt als ASCII-1967, US-ASCII, ANSI X3.4-1968, CP367, ECMA-6, ISO 646 oder RFC 20. Der Vorläufer ASCII-1963 hatte bereits die wesentlichen Funktionen mitgebracht, aber auf Kleinbuchstaben verzichtet. Erst die Mitwirkung der Internationalen Standardorganisation (ISO) und der europäischen Computer-Hersteller (ECMA) hatte ASCII in seiner heutigen Form möglich gemacht.
ASCII sollte für die frühen Computer ebenso funktionieren wie für Fernschreiber. Deshalb räumten die Experten reichlich Platz für Steuerzeichen frei: 33 der insgesamt 128 Zeichen (0 bis 31 und 127) sind nicht druckbar. Dazu zählen die Zeilenumbrüche CR und LF, der Tabulator TAB, das Alarmzeichen BEL, das Nullbyte NUL und das Löschzeichen DEL. Das Gros der Steuerzeichen regelte den Verbindungsaufbau (z.B. ACK, NAK, SYN, EOT) und ist mit den Fernschreibern im Museum gelandet.
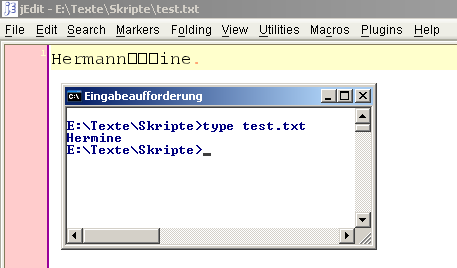
Spaß mit Steuerzeichen: Durch ASCII-Backspace (Zeichen 08) wird Hermann zu Hermine.
Ohne das Leerzeichen SP (Nummer 32), das traditionell zu den druckbaren Zeichen zählt, bleiben 94 Zeichen, die auf dem Papier sichtbar werden. 62 davon sind das lateinische Alphabet in Groß- und Kleinschreibung sowie die zehn arabischen Ziffern. Die verbleibenden 32 entfallen vor allem auf die gängigen Satzzeichen, Klammern und mathematischen Symbole.
Die Bedeutung von ASCII macht ein Blick auf die Tastatur deutlich: Die Menge druckbarer ASCII-Zeichen ist fast identisch mit dem, was ein gängiges deutsches Tastenbrett ohne Tricks darstellen kann. Allerdings beherrschen die Tastaturen ein paar zusätzliche Zeichen – in erster Linie die deutschen Umlaute.
Um solche Zeichen mit ASCII darzustellen, versuchte man es zuerst mit dem Zusammensetzen von Sonderzeichen – ähnlich wie man noch heute auf einer deutschen Tastatur ´e eingibt, um é zu schreiben. Das setzte sich langfristig jedoch ebenso wenig durch wie die nationalen ASCII-Varianten, die (mit dem Segen von ISO 646) zwölf entbehrlich scheinende Zeichen # $ @ [ \ ] ^ ` { | } ~ alternativ belegte. Die deutsche Variante ISO 646-021 alias DIN 66083 beließ # $ ^ ` an ihrem Platz und ersetzte die übrigen Zeichen mit den sieben gängigsten Sonderzeichen ä ö ü Ä Ö Ü ß und in einem wahrhaft symbolischen Akt das @-Zeichen durch den Paragrafen §.
Schon zur Zeit der ASCII-Einführung arbeiteten die meisten Computersysteme mit 8 Bit. Der erste 8-Bit-Zeichensatz, IBMs EBCDIC, entstand zeitgleich zu ASCII und war bis in die jüngere Vergangenheit auf Großrechnern in Gebrauch. EBCDIC sah unterschiedliche "Code Pages" vor, weitgehend eigenständige Zeichensätze. So enthielt das in den ersten PCs verwendete CP437 Umlaute, aber auch Linien, mit denen sich im Textmodus einfache Grafiken zeichnen ließen. Nachfolger wie CP850 sind noch heute in der Windows-Eingabeaufforderung zu bestaunen.
Ähnliche Zeichensätze entwickelten die Homecomputer-Hersteller. Apple dagegen benötigte für Mac OS Roman keine grafischen Elemente und stellte alle möglichen Sonderzeichen und griechische Buchstaben auf 8 Bit zusammen.
Zu dieser Zeit gab es jedoch bereits den Standard ISO 8859, der die 128 ASCII-Zeichen um weitere 128 ergänzt. Parallel zu den ASCII-Zeichen 0 bis 31 reservierte man Nummer 128 bis 159 für kaum benutzte Steuerzeichen. Die 96 verbleibenden Zeichen ändern sich je nach Variante. So lassen sich mit ISO 8859-1 ("Latin-1") fast alle westeuropäischen Sprachen schreiben. Insgesamt bilden zehn Varianten von ISO 8859 Spielarten des lateinischen Alphabets ab. Überschneidungen gehören zum System: Die jeweilige Zeichensatz-Variante soll in sich benutzbar sein.
Die mit Abstand populärste Variante ISO 8859-1 ist eigentlich veraltet, denn die Euro-Einführung machte ein neues Zeichen nötig. Der oft in E-Mails verwendete Nachfolger ISO 8859-15 fügt das Euro-Zeichen anstelle des Währungssymbols ¤ ein und ersetzt ein halbes Dutzend weiterer Zeichen.
ISO 8859 beseitigte die gröbsten Probleme mit Sonderzeichen. An seine Grenzen stößt das System, wenn man beispielsweise in einen mit ISO 8859-1 kodierten deutschen Text einen serbokroatischen oder polnischen Namen schreiben will.
Unter Microsoft Windows ist ein Zeichensatz verbreitet, der oft mit ISO 8859-1 verwechselt wird. In Wirklichkeit handelt es sich um CP1252 (meist als "Windows-1252" bezeichnet). CP1252 ersetzt die 32 ISO-Steuerzeichen durch druckbare Sonderzeichen; ansonsten ist es mit ISO 8859-1 identisch. Von diesem Windows-Standard gibt es neun Varianten (Codeseiten 1250 bis 1258), die allesamt Entsprechungen in den Spielarten von ISO 8859 haben.
Bizarrer Nebeneffekt: DOS-Dokumente lassen sich nicht fehlerfrei unter Windows lesen und umgekehrt. Mit dem Kommandozeilen-Befehl chcp kann der Anwender die Kodierung anzeigen; eine Anweisung wie chcp 1252 ändert die Kodierung der eingegebenen Zeichen, nicht aber die Ausgabe: Ein "ä" stellt die Eingabeaufforderung dann als "õ" dar.

Zweisprachig: Windows verwandelt einen in der Eingabeaufforderung erstellten Text in Zeichengrütze – Windows-1252 und CP850 sind nicht kompatibel.
Zu den zehn lateinischen Varianten von ISO 8859 gesellen sich noch fünf für Kyrillisch, Arabisch, Griechisch, Hebräisch und Thai. Nicht alle davon waren erfolgreich – beispielsweise konnte ISO 8859-5 nie den kyrillischen Zeichensatz KOI-8 verdrängen.
Bei anderen Sprachen geht das Zeichensätzen wie ISO 8859 zugrundeliegende Konzept überhaupt nicht auf. Vor allem Japanisch, Chinesisch und Koreanisch lassen sich nicht mit 256 Zeichen darstellen. Internationale Gremien versuchten sich daran mit ISO-2022 und EUC; Shift_JIS, Big5 und GB sind nationale Ansätze aus Japan, Taiwan und China.
Die Probleme mit japanischen und chinesischen Schriftzeichen wurden zur Keimzelle eines fast utopisch wirkenden Projekts. Noch bevor der große Internet-Boom das latente Zeichensatz-Chaos vollends in ein sprachliches Babylon verwandelte, entstand Ende der 80er-Jahre in den Xerox-Labors die Idee einer universellen Zeichentabelle für alle Sprachen der Welt: Unicode.
Was ein echtes Zeichen (ein Graphem) ist und was nicht, lässt sich nicht immer leicht entscheiden – dafür liefert bereits das deutsche ß ein Beispiel, das man als typografische Variante (eine Glyphe) von ss deuten könnte. Der Unterschied zwischen Graphemen und Glyphen beschäftigte die Sprachwissenschaftler über Jahre. Inzwischen ist die Arbeit für fast alle lebendigen und viele tote Sprachen abgeschlossen. Einige Witzbolde wollen sogar Klingonisch und Tolkiens Elbisch in Unicode aufnehmen. Unicode definiert auch Zeicheneigenschaften wie Leserichtung, Sortierreihenfolge und Kombinationsregeln.
Einmal in Unicode aufgenommen, bleiben die Zeichen erhalten: Nachträgliche Änderungen gibt es nicht, um die Eindeutigkeit der Codepunkte nicht zu gefährden. Das erklärt die langwierige Aufnahmeprozedur für neue Unicode-Zeichen. Zu den kontrovers diskutierten Themen gehören auch das Verhältnis diakritischer Zeichen zu fertig zusammengesetzten und semantisch gleiche, aber unterschiedlich geschriebene Zeichen in Chinesisch und Japanisch.
Umfang und Architektur von Unicode, das Verhältnis zu ASCII und ISO 8859-1 sowie die wichtigsten Kodierungen UTF-8 und UTF-16 sind Thema des Heft-Artikels.
Zwei Unicode-Kodierungen sollten noch erwähnt werden: Das ISO-spezifizierte UCS-2 (Universal Character Set, 2 Bytes) war mit UTF-16 identisch, solange es in Unicode nur 216, also 65.536 Zeichen gab. UTF-16 wurde jedoch um "Surrogate Pairs" erweitert, mit denen sich die seltenen Zeichen jenseits der Basic Multilingual Plane (BMP, siehe Heft-Artikel) auf 4 Bytes (32 Bit) darstellen lassen. UCS-2 kann diese Zeichen nicht abbilden.
Die technisch veralteten E-Mail-Standards aus der 7-Bit-ASCII-Zeit haben eine besonders unhandliche Kodierung hervorgebracht: UTF-7, das den gesamten Unicode-Zeichenvorrat in kompakte 7-Bit-Häppchen aufbricht. Diese können einen SMTP-Server ohne weitere Kodierung passieren.
Was die Darstellung der Unicode-Zeichen in Schriftarten angeht, gibt es technische Grenzen: Keine Schriftart enthält alle 100.000 Unicode-Zeichen, denn TrueType-, OpenType- und PostScript-Schriften sind auf 65.536 Zeichen beschränkt; nur wenige Schriftarten kennen mehrere tausend Zeichen für verschiedene Sprachfamilien.
Um die Vielfalt ein wenig einzudämmen, beschränken sich die Betriebssysteme auf sinnvolle Teilmengen. So sammelt Windows 652 Unicode-Zeichen in der Windows Glyph List (WGL-4). Damit kann ein deutsch- oder englischsprachiges Windows standardmäßig immerhin lateinische, griechische, kyrillische, arabische und hebräische Texte darstellen sowie die alten DOS-Boxen zeichnen. Ein asiatisches Sprachpaket lässt sich in den "Regions- und Sprachoptionen" von Windows hinzufügen.
Browser tauschen automatisch die Schriftart aus, wenn sie Zeichen nicht in der von der Webseite oder vom Anwender vorgegebenen Type vorrätig haben – ein Zwiebelfisch, würde man in der Druckersprache sagen.